来源:github;编译:MarsBit
TL;DR
我们提出OPML(Optimistic机器学习),它可以使用Optimistic方法对区块链系统进行AI模型推理和训练/微调。
与ZKML相比,OPML可以提供低成本、高效率的ML服务。OPML的参与要求很低:我们现在能够在没有GPU的普通PC上运行带有大型语言模型的OPML,例如7B-LLaMA(模型大小约为26GB)。
OPML采用验证游戏(类似于Truebit和Optimistic Rollup系统)来保证ML服务的去中心化和可验证共识。
请求者首先启动一个ML服务任务。
然后,服务器完成ML服务任务并将结果提交到链上。
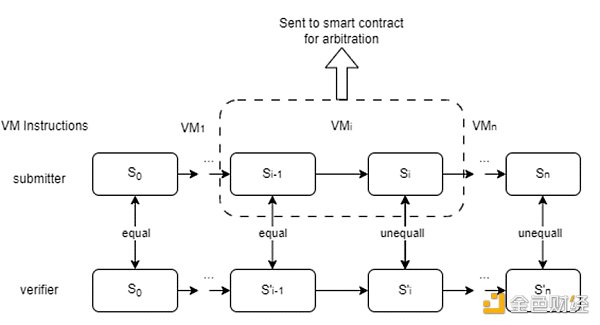
验证者将验证结果。假设存在一个验证者声明结果是错误的。它通过与服务器的验证游戏(二分协议)启动验证游戏,并试图通过精确指出一个具体的错误步骤来反驳该声明。
最后,在智能合约上进行单个步骤的仲裁。
单阶段验证游戏
单阶段精确定位协议的工作原理与计算委托 (RDoC) 类似,其中假设两个或多个参与方(至少有一个诚实的参与方)执行相同的程序。然后,双方可以用精确的方式相互质疑,以找出有争议的步骤。将步骤发送给计算能力较弱的法官(区块链上的智能合约)进行仲裁。
在单阶段OPML中:
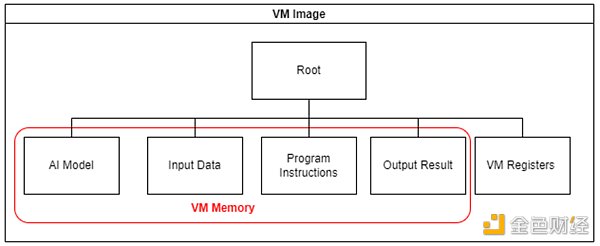
我们构建了一个虚拟机(VM)用于链下执行和链上仲裁。我们保证了在智能合约上实现的链下VM和链上VM的等效性。
为了确保虚拟机中AI模型推理的效率,我们实现了一个专门为此目的设计的轻量级DNN库,而不是依赖于流行的ML框架,如Tensorflow或PyTorch。此外,还提供了一个脚本,可以将Tensorflow和PyTorch模型转换为这个轻量级库。
采用交叉编译技术将人工智能模型推理代码编译成虚拟机程序指令。
虚拟机镜像是用默克尔树管理的,只有默克尔根会被上传到链上智能合约。(默克尔根代表虚拟机状态)
二分协议将帮助定位争议步骤,该步骤将发送到区块链上的仲裁合约
性能:我们在PC上测试了一个基本的AI模型(用于MNIST分类的DNN模型)。我们能够在VM中2秒内完成DNN推理,在本地以太坊测试环境中,整个挑战过程可以在2分钟内完成。
多阶段验证游戏
单阶段精确定位协议的局限性
单阶段验证游戏有一个严重的缺点:所有的计算必须在虚拟机(VM)内执行,这使我们无法充分利用 GPU/TPU 加速或并行处理的潜力。因此,这一限制严重阻碍了大模型推理的效率,这也与当前RDoC协议的限制相一致。
过渡到多阶段协议
为了解决单阶段协议所带来的限制,并确保OPML能够达到与本机环境相当的性能水平,我们提出了对多阶段协议的扩展。使用这种方法,我们只需要在最后阶段在VM中进行计算,类似于单阶段协议。对于其他阶段,我们可以灵活地执行计算,从而在本机环境中实现状态转换,利用CPU、GPU、TPU甚至并行处理的能力。通过减少对VM的依赖,我们显著地减少了开销,从而显著提高了OPML的执行性能,几乎与本机环境类似。
下图演示了一个验证游戏由两个阶段(k = 2)组成。在阶段1中,该过程类似于一个单阶段验证游戏,其中每个状态转换对应于一个改变虚拟机状态的单个VM微指令。在阶段2中,状态转换对应于包含改变计算上下文的多个微指令的“大指令”。
提交者和验证者将首先使用二分协议启动第二阶段的验证游戏, 以定位“大指令”上的争议步骤。此步骤将发送到下一阶段,即phase -1。第一阶段的工作原理类似于单阶段验证游戏。第一阶段的二分协议将有助于定位 VM 微指令上的争议步骤。该步骤将发送至区块链上的仲裁合约。
为了确保过渡到下一阶段的完整性和安全性,我们依赖于默克尔树。该操作包括从更高级别的阶段提取Merkle子树,从而保证验证过程的无缝延续。
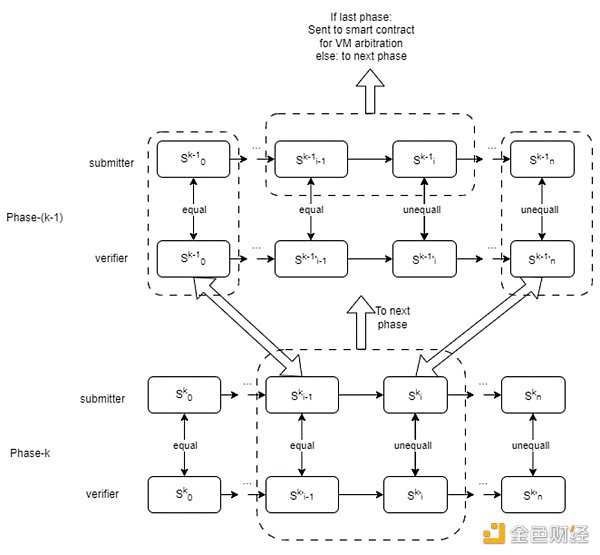
多阶段OPML
在本演示中,我们提出了 LLaMA 模型中使用的两阶段 OPML 方法:
机器学习(ML),特别是深度神经网络(DNN)的计算过程可以表示为计算图,表示为G。该图由各种计算节点组成,能够存储中间计算结果。
DNN模型推理本质上是在上述计算图上的计算过程。整个图可以看作是推理状态(Phase-2中的计算上下文)。在计算每个节点时,结果存储在该节点中,从而将计算图推进到下一个状态。
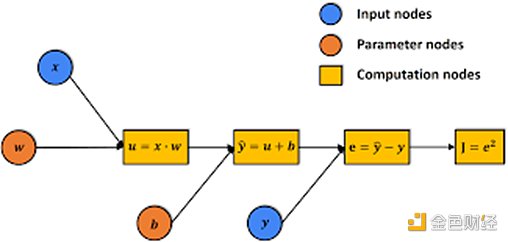
因此,我们可以先在计算图上进行验证博弈(在phase-2)。在第二阶段验证游戏中,图形节点的计算可以在本地环境中使用多线程CPU或GPU进行。二分协议将帮助定位争议节点,该节点的计算将发送到下一阶段(phase-1) 二分协议。
在第一阶段二分中,我们将单个节点的计算转换为虚拟机(VM)指令,类似于在单阶段协议中所做的操作。
值得注意的是,当计算图中单个节点的计算仍然计算复杂时,我们预计会引入多阶段OPML方法(包括两个以上阶段)。这一延长将进一步提高验证过程的整体效率和有效性。
性能改进
在这里,我们对我们提出的多阶段验证框架进行了简要的讨论和分析。
假设有n DNN计算图中的节点,每个节点需要取m VM微指令,在VM中完成计算。假设使用GPU或并行计算对每个节点的计算加速比为α 。该比率表示通过GPU或并行计算实现的加速,并且可以达到显着值,通常比VM执行速度快几十倍甚至数百倍。
基于这些考虑,我们得出以下结论:
1.两阶段OPML优于单阶段OPML,实现了计算加速α次。多阶段验证的使用使我们能够利用GPU或并行处理提供的加速计算能力,从而显着提高整体性能。
2.当比较Merkle树的大小时,我们发现在两阶段OPML中,大小为O(m+n),而在单阶段OPML中,尺寸明显大于 O(mn)。Merkle树大小的减小进一步突出了多阶段设计的效率和可扩展性。
总之,多阶段验证框架提供了显着的性能改进,确保更高效和更快的计算,特别是在利用GPU或并行处理的加速能力时。此外,减小的Merkle树大小增加了系统的有效性和可扩展性,使多阶段OPML成为各种应用的选择。
一致性与确定性
在OPML中,确保ML结果的一致性是至关重要的。
在DNN计算的本机执行过程中,特别是在不同的硬件平台上,由于浮点数的特性,可能会产生执行结果的差异。例如,涉及浮点数的并行计算,例如(a+b)+c与a+(b+c), 由于舍入误差,通常会产生不相同的结果。此外,编程语言、编译器版本和操作系统等因素都可能影响浮点数的计算结果,从而导致ML结果进一步不一致。
为了应对这些挑战并保证OPML的一致性,我们采用了两种关键方法:
1.采用定点算法,又称量化技术。这种技术使我们能够使用固定精度而不是浮点数来表示和执行计算。通过这样做,我们减轻了浮点舍入误差的影响,从而获得更可靠和一致的结果。
2.我们利用基于软件的浮点库,这些库旨在跨不同平台保持一致的功能。这些库确保了ML结果的跨平台一致性和确定性,而无论底层硬件或软件配置如何。
通过结合定点算法和基于软件的浮点库,我们为在OPML框架内实现一致和可靠的ML结果奠定了坚实的基础。这种技术的协调使我们能够克服浮点变量和平台差异带来的固有挑战,最终增强OPML计算的完整性和可靠性。
OPML vs ZKML
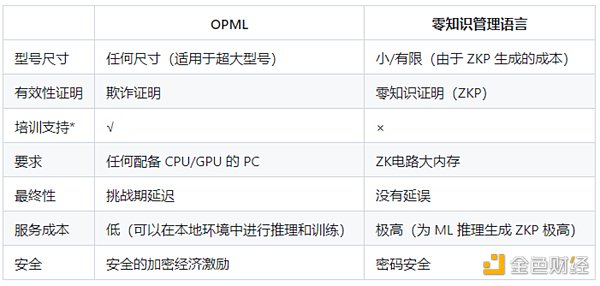
*:在当前的OPML框架中,我们的主要重点在于ML模型的推理,从而实现高效且安全的模型计算。然而,必须强调的是,我们的框架也支持训练过程,使其成为各种机器学习任务的通用解决方案。
请注意,OPML仍在开发中。如果您有兴趣成为这一激动人心的计划的一部分,并为OPML项目做出贡献,请随时与我们联系。